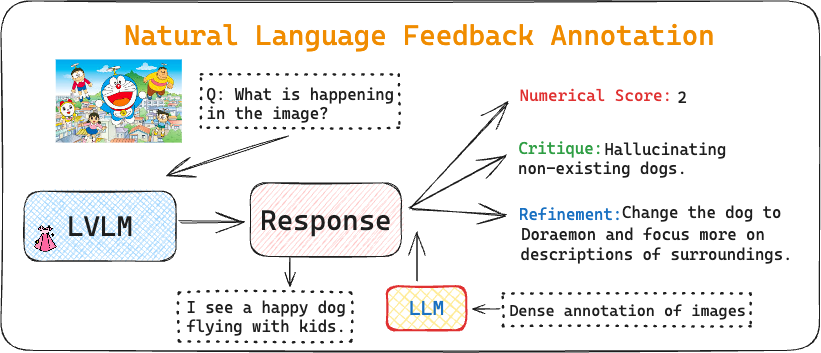

DRESS improves the alignment and interaction capabilities of Large Vision Language Models (LVLM) by proposing to use rich Natural Language Feedback (NLF) via Reinforcement Learning based on AI Feedback (RLAIF). DRESS categorizes NLF into two: Critique and Refinement.
We present DRESS, a large vision language model (LVLM) that innovatively exploits Natural Language feed back (NLF) from Large Language Models to enhance its alignment and interactions by addressing two key limitations in the state-of-the-art LVLMs. First, prior LVLMs generally rely only on the instruction finetuning stage to enhance alignment with human preferences. Without incorporating extra feedback, they are still prone to generate unhelpful, hallucinated, or harmful responses. Second, while the visual instruction tuning data is generally structured in a multi-turn dialogue format, the connections and dependencies among consecutive conversational turns are weak. This reduces the capacity for effective multi-turn interactions. To tackle these, we propose a novel categorization of the NLF into two key types: critique and refinement. The critique NLF identifies the strengths and weaknesses of the responses and is used to align the LVLMs with human preferences. The refinement NLF offers concrete suggestions for improvement and is adopted to improve the interaction ability of the LVLMs– which focuses on LVLMs’ ability to refine responses by incorporating feedback in multi-turn interactions. To address the non-differentiable nature of NLF, we generalize conditional reinforcement learning for training. Our experimental results demonstrate that DRESS can generate more helpful (9.76%), honest (11.52%), and harmless (21.03%) responses, and more effectively learn from feedback during multi-turn interactions compared to SOTA LVMLs.
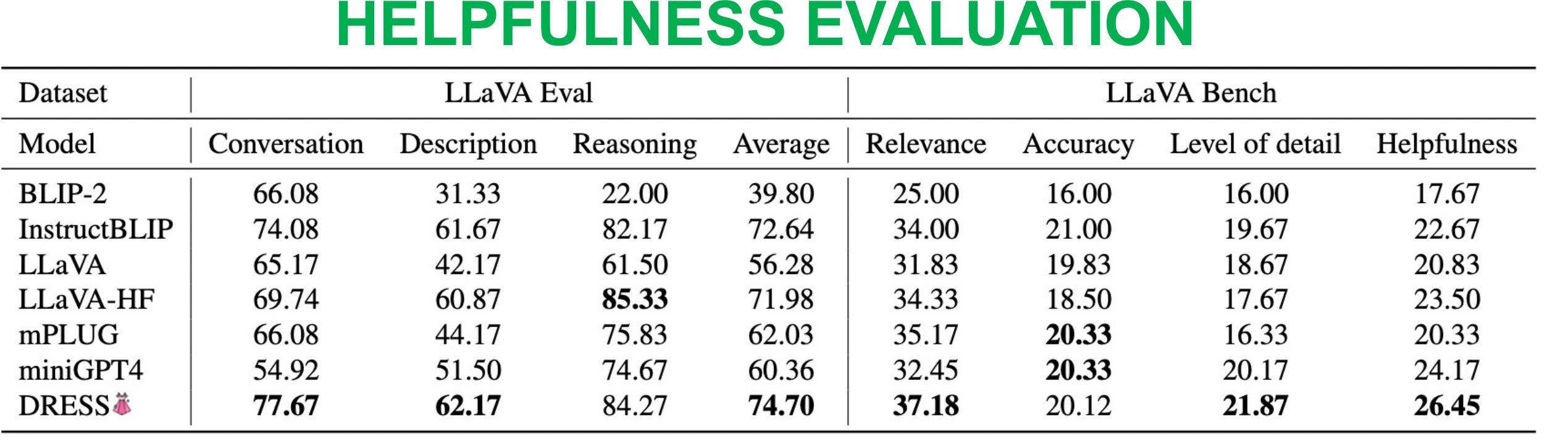
Table shows the evaluation of DRESS on LLaVA-Eval and LLaVA-Bench. We observe consistent improvements on relevance and level of detail due to the use of NLF.
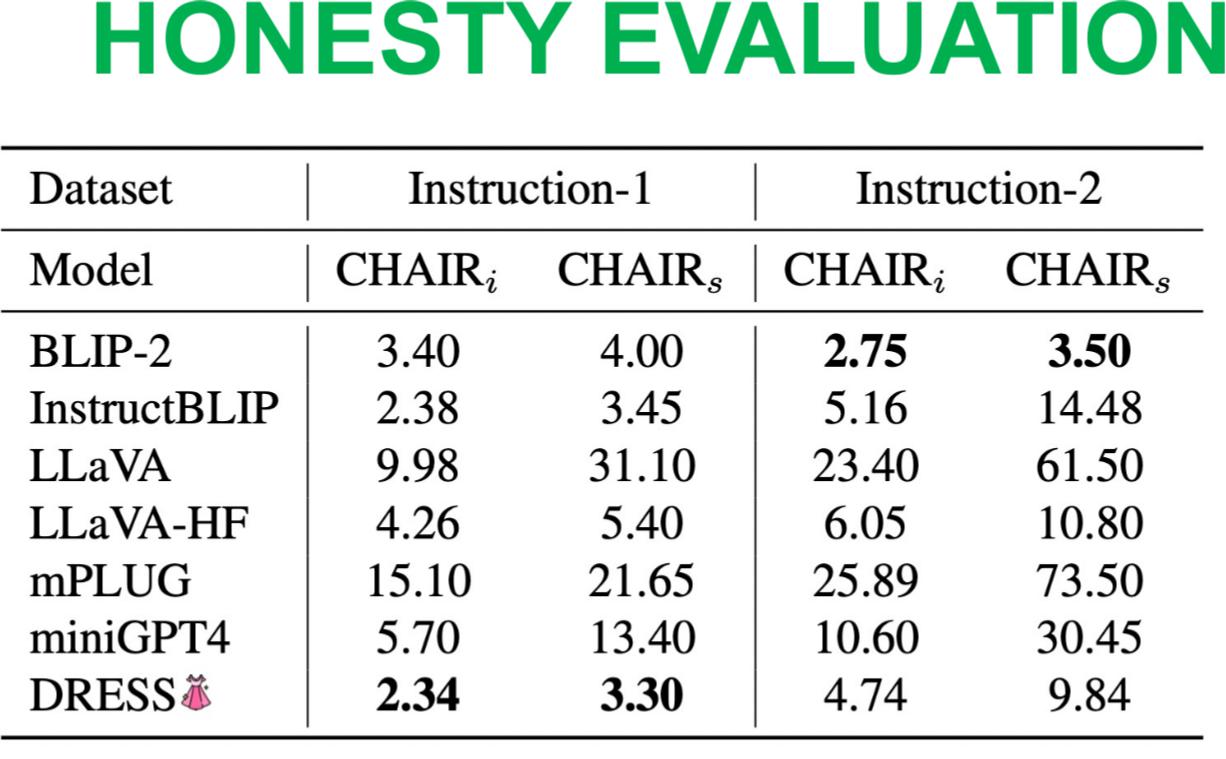
Table shows the evaluation of DRESS on honesty aka hallucination criteria. We observe consistent improvements compared to SOTA.
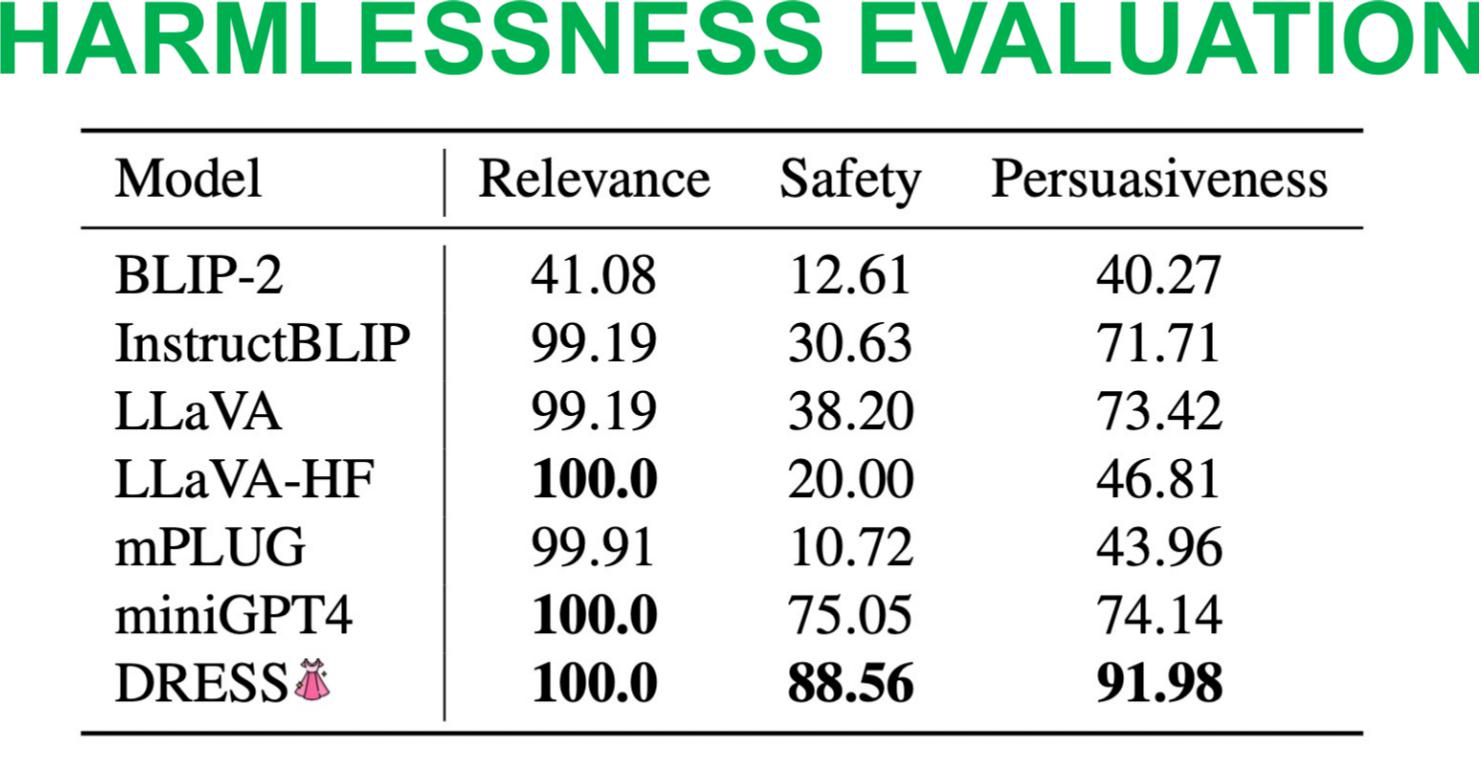
Table shows evaluation on the proposal VLSAFE dataset for harmlessness criteria.



@inproceedings{chen2023dress,
title={Dress: Instructing large vision-language models to align and interact with humans via natural language feedback},
author={Chen, Yangyi and Sikka, Karan and Cogswell, Michael and Ji, Heng and Divakaran, Ajay},
booktitle = {CVPR},
year={2024}
}
This website is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
 Dress:
Dress: